【中級者向け】計算複雑性とNP困難
前の章では「組合せ爆発」について触れました。要素数が少し増えるだけで、組合せ最適化問題の解の候補が天文学的な数字に膨れ上がり、それに伴って最適解を探すのにかかる時間も爆発的に増加していく現象です。これを計算複雑性理論の世界では 計算量 (Computational Complexity) という概念を用いて定量的に評価します。このページでは、問題の難しさを測るための基本的な考え方をもう少し詳しく説明します。
アルゴリズムの性能を評価する
Section titled “アルゴリズムの性能を評価する”問題の難しさ についての議論をするには、まずその問題を解くための アルゴリズムの性能 を議論しなくてはなりません。そこでまず、アルゴリズムの性能を評価するための基本的な考え方を理解しましょう。
計算量の増加の速さ
Section titled “計算量の増加の速さ”私たちがアルゴリズムの性能を評価する際、具体的な処理時間 (何秒かかるか) はあまり重要ではありません。それは使用するコンピュータの性能によって変わってしまうからです。重要なのは、「入力のサイズ が増えたとき、そのアルゴリズムの計算時間がどれくらい急速に増大するか」 です。
それでは、アルゴリズムの計算時間の増大の速さはどうやって理解すればよいでしょうか。1つの方法は、 が非常に大きい値を取るときに計算時間がどれだけ増大するかを極限で計算する方法です。よく知られているように、次のことが成り立ちます。
つまり、 がめちゃめちゃに大きくなっていくにつれて、
- べき乗 は平方根よりも速く発散し、
- 指数関数 は多項式よりも速く発散し、
- そして階乗 は指数関数よりも速く発散する
ということがわかります。しかも、発散の速さは最も発散が速い項に影響を受けます。他にどんなに沢山項があっても、1つでも発散の速い項が存在すれば、式全体として発散が早くなるのです。そこで、アルゴリズムの計算量の増大の速さを評価する際には、もっとも発散の速い項にのみ着目します。
さらに、定数倍の違いはグラフの縦軸方向に伸び縮みする程度の変化でしかなく、グラフの曲線の形状そのものは変化ない ので、切り捨てて考えます。
指数よりも階乗のほうが発散が速いことは、次のスターリングの公式からわかる。
ここで、 は において両者が漸近することを意味する。
これが、計算量の増加の速さを測る基本的な考え方です。それでは、これを数学的にもう少ししっかり定義する方法を考えましょう。
ランダウのビッグオー記法
Section titled “ランダウのビッグオー記法”先ほどの「指数関数は多項式より速く、階乗は指数関数より速く発散する」という主張は、次のように言い表すことができます。
これは次のように書くこともできます。
このような計算時間の増え方を表すのに、ランダウのビッグオー記法 を使うと便利です。
つまり、 であるとは、入力サイズ がある地点 を超えれば、あとはどんなに が増えても は常に 以下に収まる (上から抑えられる) という意味です。
この記号を使うと、先ほどの「最も発散が速い項のみに注目する」という部分は、次のように表すことができます。
さて、ビッグオー記法の定義によれば、実は以下のようなことも言えます。
具体的に考えてみよう
Section titled “具体的に考えてみよう”ということはできますが、逆に ということはできません。 を何倍したとしても、 が十分大きければ、 よりも のほうが大きくなっていってしまうのです。これを具体的に見てみましょう。たとえば、、 とします。そうすると、 が比較的小さいうちは
| 大小関係 | |||
|---|---|---|---|
と、確かに圧倒的に のほうが大きいです。ところが、この関係はほどなく逆転します。
| 大小関係 | |||
|---|---|---|---|
これ以降は常に が成り立ちます。
以上は単に の例を取ってきただけですが、これに限らず、どんなに を大きく設定したとしても、 はいつか必ず を追い越してしまいます。そういうわけで、 は成り立ちません。
ランダウの記号 は単に における漸近挙動を記述するのみならず、より一般に が何らかの値に収束していく際の漸近挙動を記述するのにも使われます。たとえば、指数関数のマクローリン展開
を2次の項で打ち切って、3次以降の項を無視するという操作は
などと表すことができます。この場合のランダウの記号の定義は次のように表すことができます。
なお という部分は、誤解のない限りよく省略されることが多いです。
問題の難しさを評価する
Section titled “問題の難しさを評価する”ここまでで、
- アルゴリズムの性能指標の1つは、 が増加したときにアルゴリズムの計算時間がどれくらい増えるかに注目することである
- が十分に大きいときには、最も大きな項に注目すればよい
- 最も大きな項の増加の速さを表すにはビッグオー記法を使う
ということがわかりました。このことを活用することで、問題の「難しさ」について、定量的な議論ができるようになります。
最悪計算量の定義
Section titled “最悪計算量の定義”「問題 は難しい」と一言で言っても、その意味は曖昧です。「どんな入力に対しても難しいのか?」「どんな解き方でも難しいのか?」という問題が生じてくるのです。
そこで、以下の順序で「最悪なケース」の難しさを定義していきます。
-
入力サイズを固定する。 議論の土台として、入力データの長さ (サイズ) を一律で とします。
-
「ある解法」で「ある具体例」を解く時間を考える。 ある問題 (例:ナップサック問題全体) に含まれる、特定の具体例 (例:荷物が5個の場合の特定の数値設定) を考えます。 この具体例 を、ある特定のアルゴリズム で解くときにかかる計算時間を とします。
-
最悪ケースを考える (Worst-case)。 次に、アルゴリズム の性能を評価します。 問題 には無数の具体例 が含まれますが、その中で 最も計算に時間がかかる具体例 (最悪ケース) を解くときの時間を、そのアルゴリズムの計算量 とします。
つまり、運が悪くても、このアルゴリズムなら最大でこれくらいの時間で解ける という保証をするわけです。
-
最良のアルゴリズムを選ぶ。 最後に、問題 そのものの難しさを定義します。 問題 を解くことができるアルゴリズムは と無数に考えられます。その中で、「最も高速な (効率的な) アルゴリズム」 を用いたときの計算時間を、問題 の時間計算量 とします。
少し複雑になったので、用語を表で整理しましょう。
| 記号 | 意味 | 内容の例 |
|---|---|---|
| 入力データの長さ | ||
| 問題のクラス | 「線形計画問題」「ナップサック問題」など | |
| 問題の具体例 | に含まれる特定の数値設定のインスタンス | |
| アルゴリズム | 「内点法」「動的計画法」など | |
| 具体的な計算時間 | 具体例 をアルゴリズム で解く時間 | |
| アルゴリズムの性能 | のうち 最も難しい 具体例を で解く時間 (最悪計算量) | |
| 難しさ (最悪計算量) | 最も高速な を選んだときの |
以上をまとめると、問題 の難しさ は、次のように定義することができます。
つまり 「最悪ケースの具体例を解くのにかかる時間が最も短いアルゴリズムを選んだときの、その計算時間」 を、問題 の難しさ と定義するということです。
私たちが「 が大きくなるにつれてどれほど計算時間が長くなるのか」に興味があるとき、この をオーダー記法を用いて と表し、「問題 の難しさは である」と言います。
注意: この定義が意味すること
Section titled “注意: この定義が意味すること”-
「確実に解けるアルゴリズム (厳密解法) 」のみを対象とする。 ここでのアルゴリズム は、常に正しい最適解を出力することが保証されている必要があります。 メタヒューリスティクス (遺伝的アルゴリズムやシミュレーテッドアニーリングなど) は、短時間で「最適解に近い解」を出せるかもしれませんが、それが本当に最適解である保証がないため、ここでの「問題の難しさ」の定義におけるアルゴリズム には通常含まれません。
-
「最悪ケース」について論じている。 ここで定義した「難しさ」は、あくまで「最も時間がかかる意地悪なインスタンス」に対するものです。 逆に言えば、「理論上は非常に難しい (NP困難である) 」とされる問題でも、「実用上現れるデータの範囲ではそれほど難しくない」 というケースは多々あります。 また、最悪ケースでは指数時間かかるとされていても、平均的なデータに対しては多項式時間で解けることが知られている問題もあります。
クラスPとクラスNP
Section titled “クラスPとクラスNP”ここまで「計算量」という指標で問題の難しさを定義してきました。この指標を使うことで、クラスPとクラスNPという2つの問題の難しさを定義することができます。
通常、最適化問題は「最小のコストを求めよ」という形式ですが、複雑性の理論ではこれを 「コストが 以下になる解は存在するか? (Yes / No) 」 という形式に変換して考えます。この問題と最適化問題の関係は後で説明しますが、ここではとりあえず、「決定問題は最適化問題を Yes / No で答える形式に変更したバージョンだ」という程度で理解すればOKです。
この決定問題に対して、「最悪計算量」と「実際に解けるかどうか」という2つの観点から、以下の2つのクラスが定義されます。
クラスP (Polynomial)
Section titled “クラスP (Polynomial)”クラスP に属する問題は、「多項式時間で解を見つけることができる決定問題」 です。いわゆる「効率的に解ける」問題はこのクラスに含まれると考えて良いでしょう。
決定性チューリングマシンはいわゆる「普通のコンピュータ」のことを指しています。
クラスNP (Nondeterministic Polynomial)
Section titled “クラスNP (Nondeterministic Polynomial)”多くのパズルには、「答えを見つけるのは難しいが、答えが合っているか検算 (判定) するのは簡単である」 というある種の非対称性があります。
この性質に着目したのが クラスNP です。
簡単に言えば、 「もし『これが正解だ』という証拠をくれたら、その証拠を元に、本当にYesであるかどうかを多項式時間で判定 (検算) できる問題」 がクラスNPに相当します。
注意: NPは “Not Polynomial” (多項式時間ではない=難しい) の略ではありません。正しくは “Nondeterministic Polynomial” (非決定性多項式時間) の略です。
クラスNPという名前は、「非決定性チューリングマシン (Nondeterministic Turing Machine)」(並列世界ですべての可能性を同時に試せるような仮想的なウルトラスーパーハイスペックな並列マシンのようなもの) を用いて多項式時間で解ける、という定義に基づいています。
問題の難しさの比較について
Section titled “問題の難しさの比較について”ここからは、問題同士の「相対的な難しさ」を比較する方法を考えていきましょう。そのための1つの方法は、「一方の問題がもう一方の問題の答えを教えてくれるかどうか」 です。
多項式時間還元
Section titled “多項式時間還元”ある問題 を解く手続きの中で、別の問題 を解く手続きを利用できるとします。このとき、「もし問題 を解くアルゴリズム (サブルーチン) があれば、それを使って問題 も多項式時間で解ける」ならば、問題 は問題 以上の難しさを持つと言えます。
これを厳密に定義するために、オラクル (神託) という概念を使います。オラクルとは、ある問題の入力を与えると、瞬時に (1ステップで) 正しい解を返してくれる仮想的なブラックボックスのことです。
この定義が意味することは以下の2点です。
- 「もし問題 を多項式時間で解ける (実在のプログラムが存在する) ならば、それをサブルーチンとして使うこのアルゴリズム によって、問題 も多項式時間で解ける」
- (対偶) 「もし問題 が多項式時間で解けないほど難しいならば、サブルーチンとして使われている問題 もまた (多項式時間では) 解けないほど難しい」
そういうわけで、これが成り立つ時、直感的には「問題 の難易度は問題 以上である」と言えます。不等号
は、問題の難しさの大きさを抽象的に表していると理解すればよいです。
NP困難 (NP-Hard) と NP完全問題 (NP-Complete)
Section titled “NP困難 (NP-Hard) と NP完全問題 (NP-Complete)”還元の概念を使うことで、クラスNPに関連する「最も難しい」問題群を定義できます。
NP困難 (NP-Hard)
Section titled “NP困難 (NP-Hard)”NP困難とは、「NPに属するすべての問題以上に (少なくとも同等に) 難しい問題」のことです。
なお、NP困難な問題 自身は、NPに属している必要はありません。NPよりもはるかに難しいクラス (判定すら多項式時間でできない問題など) に属していても構いません。
NP完全問題 (NP-Complete)
Section titled “NP完全問題 (NP-Complete)”NP困難 (任意のNP問題よりも難しい) 問題で、かつ 自分自身はNP (検算は簡単) である ような決定問題を「NP完全問題」と呼びます。
注意: この定義に従えば、NP完全問題は決定問題でなくてはいけないので、「ある最適化問題はNP完全問題である」という表現は適切ではないと言えます。用語の使い方には注意しましょう。。。
クラスPとクラスNPの関係
Section titled “クラスPとクラスNPの関係”「NP完全問題」という「NPの中で最も難しい問題」が定義できたことで、クラスPとクラスNPの関係についてより深く議論することができます。
P は NP の部分集合
Section titled “P は NP の部分集合”定義から明らかなように、クラスPに含まれる問題は、すべてクラスNPに含まれます ()。 なぜなら、自力で多項式時間で「解ける」問題は、当然ながら多項式時間で「検算」もできる (自分で解いて答え合わせすればよい) からです。
P vs NP問題
Section titled “P vs NP問題”では、その逆、つまり 「検算が簡単な問題は、すべて解くのも簡単なのか? ()」 という問いはどうでしょうか。実は、この問いは現代の計算機科学における最大の未解決問題の一つである 「 予想」 と呼ばれる問題です。この問題については、現時点では証明も反証もされていません (少なくとも、証明されることも反証されることも非常に難しいことだけはわかっています) 。
以上は素朴な見方ですが、歴史的には 予想に決着をつけるために考案された様々な手法が、その方法では原理的に証明も反証も不可能であることが後から証明される という泥沼の様相が繰り広げられてきました。
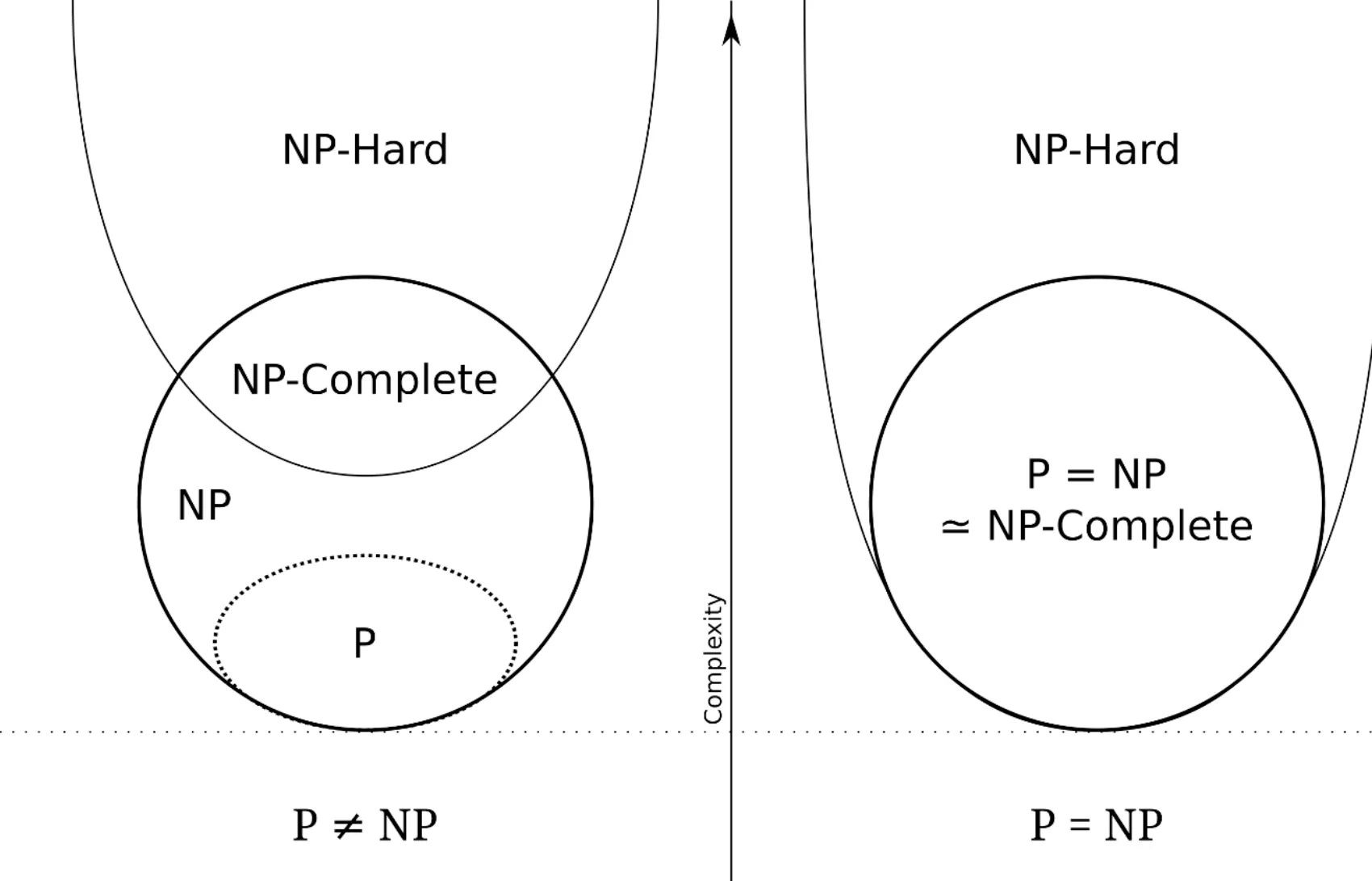 Euler diagram for P, NP, NP-Complete, and NP-Hard set of problems. Licensed under the Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic and 1.0 Generic license. Attibution: Behnam Esfahbod
Euler diagram for P, NP, NP-Complete, and NP-Hard set of problems. Licensed under the Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic and 1.0 Generic license. Attibution: Behnam Esfahbod
現在では、NP完全な問題は数千個程度見つかっているにも関わらず、どの1つに対しても多項式時間で解けるようなアルゴリズムが見つかっていないことから、多くの研究者は (検算は簡単だが解くのは難しい問題は、実際に存在する) と予想しています。
厳密解を諦める
Section titled “厳密解を諦める”さて、私たちが産業応用で直面する組合せ最適化問題の多くは 「NP困難」 に属します。これが意味することは重大です。
と予想される現在、NP困難な問題の厳密解 (数学的保証のある正解) を多項式時間で求めるアルゴリズムは存在せず、少なくとも問題の大きさ に対して指数関数的に計算時間がかかることとなります。そのため実用的な方法で問題を解くには「完璧さ」を諦め、アプローチを抜本的に変える必要があります。
最悪計算量の定義の箇所でも少し触れたように、ここまでの話は最悪な場合の計算量を考慮する話でした。つまり最も困難なケースを考慮する話であり、平均的にはそこまでめちゃめちゃな計算時間の増え方をするとも限りません。そこで、発想を転換して、
- 平均的な問題インスタンスについては、ほぼ厳密解に近い正解を与える。
- 稀に現れる最悪なインスタンスについては、それなりに。
というものを目指します。
近似解法とヒューリスティクス
Section titled “近似解法とヒューリスティクス”このようなアプローチは、得られる解の数学的厳密さに着目すると大きく2つに分類されます。
- 近似解法:
- 理論上の最適解から一定以内の近さの解を求める。
- 得られた解は「厳密解からの近さ」が保証される (解のコスト間数値は厳密解のコスト関数値の◯◯%以下であるなど)。
- ヒューリスティクス:
- 経験的に (統計的に) 良い解が得られることがわかっている方法を使う。
量子アニーリング (QA) やシミュレ―テッドアニーリング (SA) などは、ヒューリスティクスとして扱われます。つまり、数学的に厳密ではなく、またどれほど正しい解を与えてくれるかの確実な保証も不十分だが、平均的な問題に対してはかなり良い答えをくれるものとして理解されています。
それでは、実際問題としてQAやSAはどれほど良いのか? もっと厳密解に近づけるにはどうすればよいのか? そのような問いが、現在の研究の中心課題となっています。